There is oft-quoted advice that Kafka does poorly as a job queue. I’ve experienced this myself, and I wanted to formalize it a bit.
I’ll use the common architecture of a Web application submitting background jobs to workers via Kafka (for example, to generate a PDF of some report). Except for the use of Kafka in this role, this is common in Web applications, and (speaking from experience!) when Kafka is already deployed, there is an impulse to use it instead of deploying yet-another queue system.
Note: when Queues for Kafka (KIP-932) becomes a thing, a lot of these concerns go away. I look forward to it!
What I want to characterize here is the worst-case “unfairness” of jobs being assigned to workers. There are many other reasons to not use Kafka as a job queue, but this unfairness is (in my view) the strongest reason. In most queues, you put work into the queue and every worker… well, works until all the work is done. It sound obvious, but that’s the raison d’être for these things! When (mis-)using Kafka as a queue, this is not the case: work can get unfairly assigned to one worker, even if other workers have nothing to do. So, how many jobs can one worker be assigned, before any other worker is given work? This can be worked out with this formula:
WorstCaseJobsPerConsumer = (Partitions / Consumers) * Producers
To work an example, say you have a topic with 16 partitions, because you would like to be able to scale up to 16 consumers at peak times, but, at your current load you only predict you need 4 consumers processing jobs. Further, say you have 5 producers (Web application servers, here - Gunicorn processes, Kubernetes pods, whatever) that receive an API call and put a job onto this Kafka topic. Imagine these Web workers are behind a load balancer which routes API calls in a round-robin fashion to each of those 5 Web workers. Pretty typical architecture right?
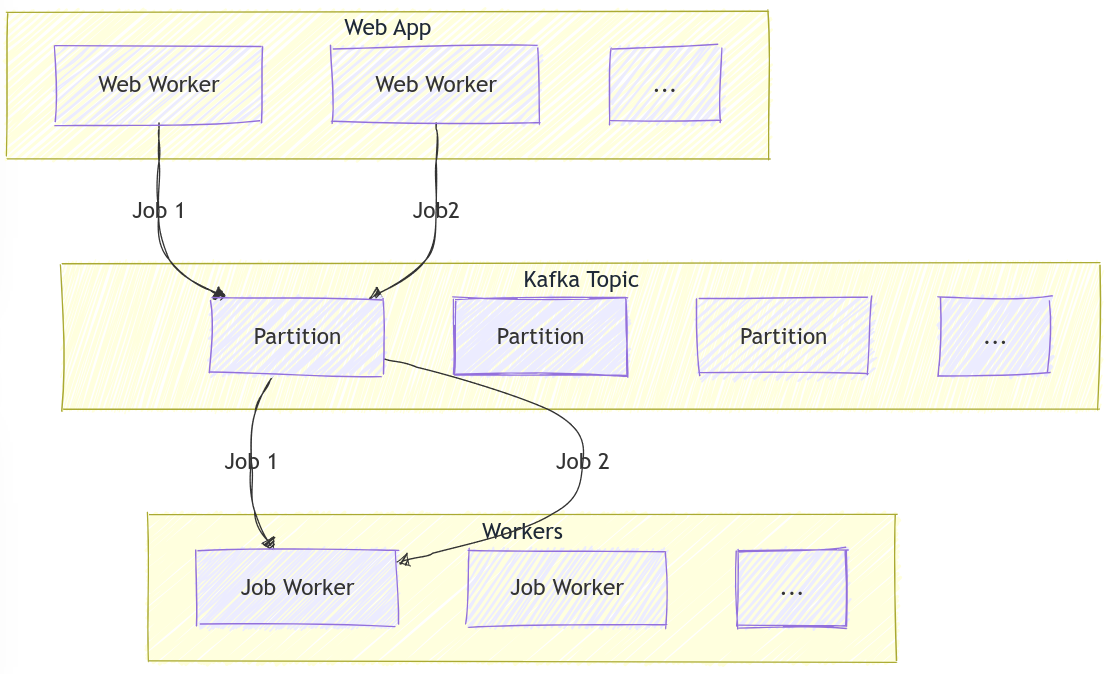
Plugging these numbers in, we get (16 / 4) * 5 == 20: that means, if you’re unlucky, the
next 20 jobs coming along could all be routed to a single consumer, and that
consumer has to churn away at those 20 jobs while its 3 counterparts will sit idle. How this would
happen is by the following somewhat unlucky sequence of events:
- Before any API calls are made, the 4 worker processes start up, and each take 4 of the 16 topic’s partitions, so that the partitions are fairly shared.
- 20 API calls are made by clients.
- The load balancer round-robins these 20 requests, giving 4 requests each to the 5 Web workers
- Each of these Web workers puts those 4 records onto 4 of the topic’s partitions in a round-robin fashion. And, because they do not coordinate this, they might choose the same 4 partitions, which happen to all land on a single consumer.
This exact sequence of events is rare, but milder variations of this happen constantly when Kafka is used this way, at a low volume - such as only half, or three-quarters of your workers being busy, while the remainder are idle and there’s work queued, just sitting there.
To decide if this matters to your application, think about your peak periods
and how many jobs might be created in that period, and what the latency
expectations are for those jobs. If it’s a small internal application used by,
say, 15 users, and they all (in the same instant) request 1 job that takes 5
minutes to run, then those 15 jobs can land on the same consumer and the queue
takes 75 minutes to clear, leading to some of those users being very unhappy.
This doesn’t always happen, but it can.
On the other hand, if you have 200 users each requesting 1 job and those jobs
take 1 second to run, these 200 jobs will be much more fairly distributed and
all workers will be contributing to clearing that queue. So where, exactly, is
this cutoff? As a rule of thumb, if you have at least
WorstCaseJobsPerConsumer * Consumers jobs in-flight in your peak period (in
the above example, this is 20 * 4 == 80 jobs), then you can be sure that all
your workers are doing some work, because there are enough jobs to overcome
the aforementioned worst-case behaviour. If there are fewer jobs than this,
you run the risk that some workers will not be pulling their weight.
Please note that I’m completely ignoring varying job run times. That makes this problem significantly worse, because again, work is assigned to workers on a record-by-record basis, irrespective of how long those jobs take. A long job will block a short job and there’s nothing you can do about it.
I am not trying to say Kafka is a bad tool - what I am saying is it was not designed for such a low volume. It was designed for exactly the opposite (millions or billions of records) where a conventional single-node message broker simply cannot keep up. It strips away a lot of the very useful features of these conventional brokers in order to go faster. If you don’t need that speed, you are losing a lot in that trade-off!
In conclusion: the oft-quoted wisdom is right; Kafka is not a good job queue, especially not at particularly low volumes, at least until Queues for Kafka (KIP-932) comes along.