Summary: Keystream reuse
Key: WhyDoFartsSmell?SoTheDeafCanEnjoyThemAlso.
I usually treat disassembling/debugging as a bit of a last resort, so I figured I’d challenge myself and lean on IDA Pro more heavily than usual. I ended up making a lot of mistakes and incorrect predictions, but learned some things and generally had a great time solving this challenge.
What we have
A stripped 64-bit Linux executable and a packet capture file.
We also know that we’re going to encounter some crypto, given that this challenge came from the “crypto” category.
I downloaded the compressed TAR archive and opened it up, finding the aforementioned
binary and PCAP. Running file on the executable yielded (line-breaks added):
$ file ./pillowtalk-stripped
pillowtalk-stripped: ELF 64-bit LSB executable, x86-64, version 1 (SYSV),
dynamically linked (uses shared libs), for GNU/Linux 2.6.24,
BuildID[sha1]=0x660940b02c09984520b7cae79e4a3b5999452a58, strippedLiving up to its name, the executable was stripped. This means that there would be fewer human-readable function and variable names, forcing us to reverse-engineer more of the program than we’d typically have to.
Peeking at packets
While my teammates worked on making useful changes to the very hackable multiplayer FPS/RPG game to let them run really fast and kill boars quickly, I opened the packet capture in Wireshark and looked at what we had:
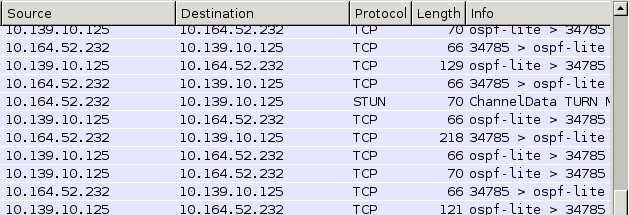
I was excited to see ospf-lite, because I’d worked with OSPF on Cisco routers before,
and it got me thinking it might be a problem involving
Dijkstra’s algorithm or something.
Needless to say, the challenge had nothing to do with OSPF and I got my hopes up for
nothing.
Digging deeper, Wireshark couldn’t interpret the packets as anything more than TCP, and neither could I. All I could tell were that the packets didn’t have a structure I recognized. I assumed it was either compressed or encrypted, but wasn’t sure.
Looking a little closer, I noticed messages are preceded by a four-byte big-endian length, so the receiving end knows how much data to expect.
From the outside in
Before diving into the disassembly, we want to figure out how the program works, from a less detailed point of view. This will help us make sense of the disassembly more quickly. To me, looking for a vulnerability in the program’s disassembly without knowing what the program does is a bit like trying to change the oil in a car before knowing what a car is.

Running the program with no arguments gives us helpful messages about how to use it. Eventually, we come to see that this program can operate either as a client or a server:
$ ./pillowtalk-stripped --host 5000
[+] Running in server mode.
- Created socket
- Socket bound to port 5000
- Listening for connectionWhen two instances of the program are run, one as a server and the other as a client connecting to the server, the programs take turns sending and receiving lines read from the keyboard, in lockstep. Said another way:
- The server waits for input on the keyboard
- The server sends that data to the client
- The client receives the data and displays it
- The client waits for input on the keyboard
- The client sends that data to the server
- The server receives the data and displays it
- Repeat!
Now that we know how the program works at a high level, we can start examining the
protocol. If we use netcat, we can simulate
a client connection and see what the server does:
$ netcat 127.0.0.1 5000 | hexdump -C
00000000 b1 44 2a df aa 2c f3 bd 6d dc 7d e4 8a 03 23 63 |.D*..,..m.}...#c|
00000010 81 b0 0a 5e f4 dc 50 58 56 1a 9c 42 31 26 54 63 |...^..PXV..B1&Tc|We see that, upon a TCP connection being made, the server immediately sends 32 bytes of apparently random data. The program doesn’t appear to accept a second connection, so we kill it and restart it. Upon connecting a second time, the data appears to be different:
$ netcat 127.0.0.1 5000 | hexdump -C
00000000 d9 0d 31 e5 c2 c5 08 50 08 63 96 bc cf 1e ba d4 |..1....P.c......|
00000010 75 1e b4 ca 1a 1d bb 62 de 99 65 7e 5a 6c c2 0b |u......b..e~Zl..|This leaves us with a question: where does this random data come from? To answer that,
we can run the program under the supervision of
strace.
We need to go deeper
strace runs a program like normal, except that it shows all of the
system calls that the program makes. It’s a
really great way to quickly figure out what a program does, as far as interacting with
the outside world goes.
We’ll run the program in server mode under strace, and then connect to to it using
netcat:
$ strace -x ./pillowtalk-stripped --host 5000
open("/dev/urandom", O_RDONLY) = 5
read(5, "\x41\xcd\x2f\x59\x6a\x90\x4c\xa3\x0d\x6c\x60\xce\x99\x7d\xeb\xd1\x9c\x4e\x38\xc0\xc3\xd0\x6e\xc2\xbe\x9b\x82\x12\x4f\x16\x8e\xbc"..., 4096) = 4096
sendto(4, "\x5e\xba\xd0\x48\xa4\xe0\xb9\xa2\x67\xff\xf9\x8d\xb9\x17\xc8\x08\xd7\xda\xdb\x66\x10\x0a\x29\xeb\x97\x27\xa2\x58\x4d\xa8\x9f\x3a", 32, 0, NULL, 0) = 32When we make a connection with netcat, we see that the server opens /dev/urandom
and reads 32 bytes of random data, and then sends 32 bytes to the client. However, the
32 bytes that it sends across the wire are totally different from the 32 bytes it
reads.
Very curious!
As it happens, the server and the client mode of this program do the same thing. The client establishes a TCP connection, the server reads 32 bytes of random data, mutates it, and sends it to the client. The client then does the same thing, sending its own mutated 32 bytes to the server.
What happens if we delete /dev/urandom and replace it with a link to /dev/zero, so
that the program will always read 32 bytes of all zero bits?
It turns out that the data sent will always be the same, regardless of program being in client or server mode and regardless of things like UID and time.
Given that the PCAP appeared to have random data in it, I made an inductive leap and guessed that the two programs were doing a key exchange. If there was a weakness in the key exchange algorithm, we could take the two “halves” from the PCAP to derive the shared key, and use that to decrypt the rest of the PCAP!
I decided now was a good time to jump into IDA.
Disassembling
Firing up IDA Pro and starting from a call to
accept and working outwards, I was able to
confirm my observation that the client and the server both read from /dev/urandom:
.text:0000000000400CF4 client_mode_requested: ; CODE XREF: sub_400BE0+A5j
.text:0000000000400CF4 ; sub_400BE0+F4j
.text:0000000000400CF4 cmp [rbp+server_mode], 0
.text:0000000000400CFB jz server_mode_requested
.text:0000000000400D01 movzx edi, [rbp+port]
.text:0000000000400D05 call server_mode
.text:0000000000400D0A mov [rbp+fd], eax
.text:0000000000400D0D jmp read_devrandom
.text:0000000000400D12 ; ------------------------------------------------------------
.text:0000000000400D12
.text:0000000000400D12 server_mode_requested: ; CODE XREF: sub_400BE0+11Bj
.text:0000000000400D12 mov rdi, [rbp+address]
.text:0000000000400D16 movzx esi, [rbp+port]
.text:0000000000400D1A call client_mode
.text:0000000000400D1F mov [rbp+fd], eax
.text:0000000000400D22
.text:0000000000400D22 read_devrandom: ; CODE XREF: sub_400BE0+12Dj
.text:0000000000400D22 lea rdi, filename ; "/dev/urandom"
.text:0000000000400D2A lea rsi, modes ; "rb"In fact, there is very little difference between the server and client modes. They largely share the same code paths, which made things a little easier.
Following the disassembly further, we see that both server and client call the same
function to convert their random bytes to the data they exchange. Inexplicably, the
function is also passed the null-terminated string "\t". Given that this was a CTF
challenge, I had a feeling this was meant to be confusing, so I mostly ignored it.
.text:0000000000400D22 read_devrandom: ; CODE XREF: sub_400BE0+12Dj
.text:0000000000400D22 lea rdi, filename ; "/dev/urandom"
.text:0000000000400D2A lea rsi, modes ; "rb"
.text:0000000000400D32 call _fopen
.text:0000000000400D37 mov rsi, 32 ; size
.text:0000000000400D41 mov rdx, 1 ; n
.text:0000000000400D4B lea rdi, [rbp+random] ; ptr
.text:0000000000400D4F mov [rbp+stream], rax
.text:0000000000400D53 mov rcx, [rbp+stream] ; stream
.text:0000000000400D57 call _fread
.text:0000000000400D5C mov rdi, [rbp+stream] ; stream
.text:0000000000400D60 mov [rbp+unused1], rax
.text:0000000000400D67 call _fclose
.text:0000000000400D6C lea rdx, tab ; "\t"
.text:0000000000400D74 lea rsi, [rbp+random]
.text:0000000000400D78 lea rdi, [rbp+keyderiv_out]
.text:0000000000400D7C mov [rbp+tab], eax ; Why a tab?
.text:0000000000400D82 call key_derivkey_deriv is called twice:
- To mutate the 32 bytes of random data before sending on the network
- To combine the original 32 bytes and the received 32 bytes into a symmetric key
The key_deriv function was enormous — I didn’t really know how to approach
it. It made use of a little over 2 kilobytes of stack variables, and fairly large
bits of code seemed to repeat hundreds of times, using different stack variables each
time.
NB: In hindsight, I realize key_deriv was a terrible name for this function.
However, that’s what I called it during the CTF, and I want to tell the story as it
happened, embarrassing bits and all!
For reference, it started from the yellow arrow and went to the end of the blue bar. For you folks that don’t use IDA, the blue is all of the executable code in the program. That’s right: this one function took up close to 80% of the total executable code.
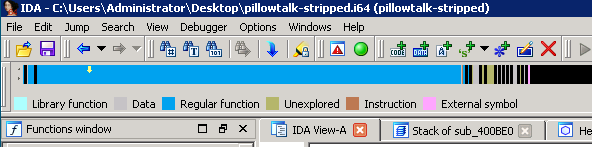
The executable was 36K in size. Certainly not huge, but for a Linux console program, it felt like a lot to reverse!
Looking at the instructions used, I had a hunch that this key exchange was based on symmetric cryptography — that is, it used a needlessly complex hash function or block cipher to obscure the relationship between the exchanged data and the agreed-upon key instead of using a proven public-key algorithm like RSA or Diffie-Hellman. Given that there is (as far as I know) no secure way to exchange a symmetric key without the advanced mathematics used by the above two methods, it would be a not-so-simple matter of using a some LD_PRELOAD shimming and a little creativity to replay the encrypted conversation back to the program and let it do the decrypting for me.
I decided that, if I was right and the vulnerability lay in this function, I would have to come back to it later. I was not ready to follow that rabbit hole just yet.
Stepping over the rabbit hole
Jumping ahead, I saw the 32 bytes returned from the key_deriv call mutated into
1024 bytes by two functions. That 1024 bytes was combined with whatever was read from
the keyboard using bitwise xor
before sending the data across the network, answering a number of questions at once:
- The random-looking data in the PCAP was certainly encryption, rather than compression
- The 32 random bytes exchanged by the two programs was indeed a key exchange
- The encryption was some form of stream cipher
Although the keystream generation function was significantly smaller than the
key_deriv function, I didn’t spend much time trying to understand it. One thing did
jump out at me, however:
.text:000000000040141B sar eax, 31
.text:000000000040141E shr eax, 24
.text:0000000000401421 add eax, ecx
.text:0000000000401423 and eax, 0FFFFFF00hThe and at the end combined with the shifting above it appeared to cause an entire
byte of entropy to be lost per loop iteration. I decided that was another rabbit hole
that would involve some hardcore math, so I didn’t dig much deeper.
Needless to say, that was totally wrong and I feel really dumb jumping to that conclusion. More on that later.
I elected to review the part of the code where the keystream was combined with the plaintext again. This time, I noticed a weakness:
.text:0000000000401004 mov [rbp+count], 0 ; Index into packet
.text:000000000040100E mov [rbp+var_A30], rax
.text:0000000000401015
.text:0000000000401015 encrypt: ; CODE XREF: sub_400BE0+481j
.text:0000000000401015 mov eax, [rbp+count]
.text:000000000040101B cmp eax, [rbp+packet_size?]
.text:0000000000401021 jnb loc_401066 ; Leave the loop
.text:0000000000401027 mov eax, [rbp+count]
.text:000000000040102D movzx ecx, [rbp+rax+keystream]
.text:0000000000401035 mov eax, [rbp+count]
.text:000000000040103B movsx edx, [rbp+rax+packet_buf?]
.text:0000000000401043 xor edx, ecx ; Encrypt one byte
.text:0000000000401045 mov sil, dl
.text:0000000000401048 mov [rbp+rax+packet_buf?], sil
.text:0000000000401050 mov eax, [rbp+count]
.text:0000000000401056 add eax, 1 ; Increment the index
.text:000000000040105B mov [rbp+count], eax
.text:0000000000401061 jmp encryptA stream cipher relies on the fact that keystream is never reused. That is, any given “chunk” of keystream should only ever be used to encrypt one “chunk” of plaintext.
In this program, the keystream generation function is only ever called once: after the key exchange. That keystream is then reused for every single message ever sent. This means that the messages we have are in depth, and we can perform a reused key attack. This is something I have had to exploit once before for a previous Capture-the-Flag, and it was just as easy then as it is now.
Breaking and entering
When a key is reused in a stream cipher, the security degrades to that of an XOR cipher with a repeating key, which can be easily broken:
- Stack Overflow: “What’s wrong with XOR encryption?”
- Project Euler #59: “Breaking XOR encryption”
- Reverse Engineering SE: “Breaking multibyte XOR encryption”
The trick to breaking this kind of cipher is to figure out how long the key is, and
where it repeats. In our case, the keystream is 0x400 bytes long which is longer
than any one message. This means that we will never see the keystream reused within
one message.
However, because the count variable (in the above disassembly) is used as the index
both into the keystream and into the packet buffer, the keystream is reused from
the beginning every time a new packet is sent.
In other words, the nth keystream byte is used to encrypt the nth plaintext byte in every single message, and that nth keystream byte never changes.
Imagine these are our three captured ciphertexts (hex-encoded):
AABBCCDDEE
112233445566778899
FFFFFFFFWe create new ciphertexts from the nth bytes of the above ciphertexts,
producing AA11FF, BB22FF, CC33FF, etc. Each of these new ciphertexts is
effectively encrypted under a single-byte key. This is trivial to break.
What do we get out of breaking mangled ciphertext?
Breaking one of these new ciphertexts yields us a single byte of the original keystream, allowing us to decrypt one ‘column’ of the original ciphertexts.
Knowing this, this is what I did:
- Open the PCAP with Wireshark and export the TCP stream as “C arrays”
- Convert the arrays to hex-encoded strings, one packet per line (using a Vim macro)
- Using a modified form of the code here, produce new ciphertexts from the nth byte of each packet and decrypt each with every possible key
- Using the principles of frequency analysis, manually recover the keystream byte-by-byte
- ???
- Profit
After about an hour of decrypting the messages, this hint was released by the coordinators:
23:28 -!- RyanWithZombies changed the topic of #gits-ctf to:
[...] Pillowtalk: the giant function is "curve25519-donna"At that point, two things became very apparent:
- I was really glad I didn’t spend much time trying to reverse that enormous function
- I can’t tell symmetric and asymmetric cryptography apart in assembly language
I proceeded to finish decrypting the texts yielding us the flag, 200 points, and a brief period as 5th place on the doge-decorated scoreboard.
Yes, we were “Memory Fist” and no, I have no idea where that name came from. We change names a lot.
Wrap up
After the CTF, I had two questions I wanted to answer:
- What stream cipher was used to generate the keystream?
- What was that tab string doing in the key exchange?
I decided I would revisit the two functions that produced the keystream from the agreed-upon key first. Upon reviewing the first of the two functions, this snippet jumped out at me:
.text:00000000004012AE fill_with_i: ; CODE XREF: KSA+4Cj
.text:00000000004012AE cmp [rsp+count], 256
.text:00000000004012B6 jge exit_loop
.text:00000000004012BC mov eax, [rsp+count]
.text:00000000004012C0 mov cl, al
.text:00000000004012C2 movsxd rdx, [rsp+count]
.text:00000000004012C7 mov rsi, [rsp+output]
.text:00000000004012CC mov [rsi+rdx], cl
.text:00000000004012CF mov eax, [rsp+count]
.text:00000000004012D3 add eax, 1
.text:00000000004012D8 mov [rsp+count], eax
.text:00000000004012DC jmp fill_with_iIt fills a 256-byte array by populating each cell with its index. The first cell is set to 0,
the second to 1, and so on. It wasn’t apparent during the competition, but it was now:
I was looking at the first step (of two) of
RC4’s key scheduling algorithm. That means that
the first mystery function sets up RC4’s internal 256-byte state, and the second mystery function
uses it to produce an arbitrary (in this case, 0x400 bytes) of keystream, which fits with the
specification of RC4.
To answer the second question, I did a little reading on curve25519-donna and found an implementation on Github that has this in the README:
To generate the public key, just do
static const uint8_t basepoint[32] = {9};
curve25519_donna(mypublic, mysecret, basepoint);The ASCII code for the tab character is 9. I guess IDA interpreted the basepoint
array as the string "\t". That was easy!
Mysteries: solved.